

對於需要從數據中獲取洞察的行銷長而言,數據品質至關重要,89% 的採購決策者都認同這是他們的首要任務。本文將揭示當前詐欺問題的現況,並說明 Kantar 如何透過人工智慧及其他先進解決方案來解決這些問題。
對於需要從數據中獲取洞見的行銷長(CMO)而言,數據品質至關重要,89% 的買家都認同這是他們的首要任務(資料來源:《Greenbook》,2023 年 GRIT 洞察實務報告)。
隨著越來越多的買家、賣家和供應商意識到必須解決這個問題,近期一項業界品質承諾正逐漸獲得更多支持。
正如市場研究協會(Market Research Society)執行長 Jane Frost 所言: 「欺詐活動正變得日益精巧,特別是在線上研究領域。這對我們產業的未來構成了重大風險。」
數據品質本應是洞察購買者可以信賴的基本要素,但猖獗的欺詐行為卻已持續多年。而這卻是整個產業中一個奇怪地鮮少被討論的話題。样组 逐漸演變成本十年的廣告欺詐或點擊農場——且正迅速走向產業化。
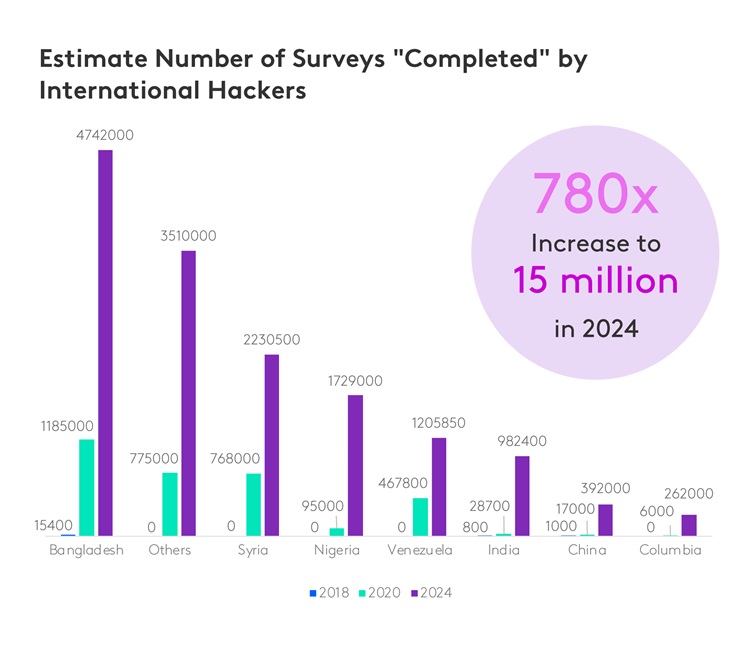
更糟的是,隨著詐騙率上升,所產生的數據偏差也隨之增加。
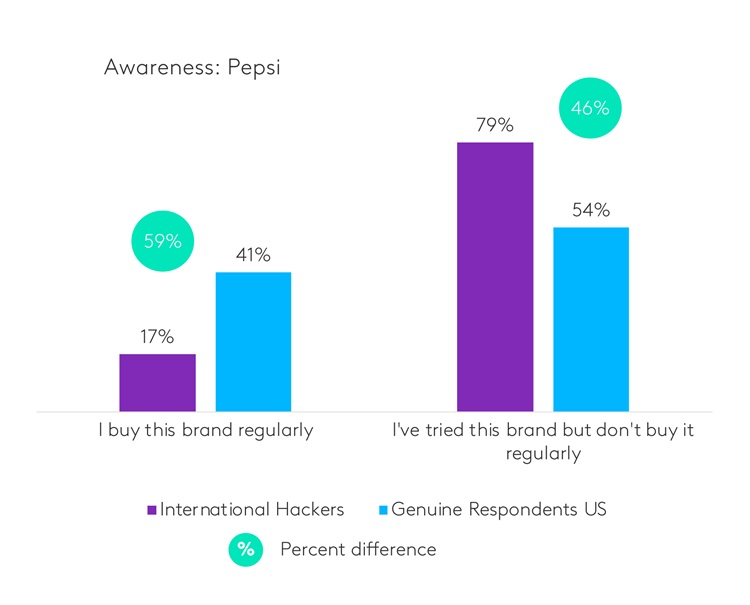
本文將揭露詐欺問題的現況,以及 Kantar 如何透過人工智慧及其他先進解決方案來解決此問題。
全球範圍內,有三大產業挑戰影響著調查樣本庫:
1. 爭奪受訪者注意力——我們該如何爭取受訪者寶貴的時間?
2.日益嚴格的資料隱私合規要求:例如 GDPR 與 CPPA 便有所不同。
3.線上詐欺問題日益嚴重。 「核對率」——即因品質低劣而被拒收的樣本所佔比例——在過去三年中上升了約 300%,且客戶在田野調查後拒收的數據比例高達 40%。
样组 必須以智慧且具策略性的方式應對這三個因素。
1. 爭奪眼球
這一切始於我們如何對待受訪者;我們不將他們視為商品,而是視為珍貴的資源。我們不斷探索如何優化提問方式、調整訪談長度(LoI),以及如何增加遊戲化元素。透過回應他們的疑問並給予妥善對待,我們將受訪者視為有血有肉的個體。我們運用獨特的問卷配對演算法,為每位獨特的受訪者進行精準配對,確保合適的人以合適的步調完成合適的問卷。 此舉有助於降低中途退出與篩選淘汰率,使問卷完成率較業界平均高出 175%。透過將受訪者視為受重視的對象,並結合先進样组 我們發現受訪者不僅感到滿意,參與度也相當高。他們在 Trustpilot 上給予我們的應用程式 4.2 分的評價,並留下諸如:「氛圍非常積極,我從線上問卷中學到了很多,同時我的銀行帳戶也持續笑逐顏開!」等正面評價。
2. 日益嚴格的資料隱私合規要求
Kantar 在業界討論及工作小組(例如 ESOMAR)中扮演領導角色。我們亦擁有專屬的內部專家團隊,持續監控隱私與同意相關法規,並確保我們具備適當的技術解決方案,以進行資料的蒐集、儲存及刪除。
例如在中國,我們擁有專門符合《個人資料保護法》(PIPL)的樣本管理平台,用於進行中國國家市場監管總局(CAC)核准的資料蒐集,並提供一系列針對市場特性的優化方案。 該平台完全位於中國網絡空間內,並可透過程式化方式存取我們全資擁有的微信样组:觸及 150 萬名較難接觸的受訪者。我們還設有多層防欺詐及品質檢查機制,確保每個微信帳號皆連結至真實且唯一的銀行帳戶。經雜湊處理的 ID 及問卷連結均採用 MD5 及 Wave Secret 加密,以減輕駭客造成的虛假完成及欺詐性回應。
3. 日益猖獗的網路詐騙
超過三分之二的資料品質警示(69%)歸因於各類詐欺行為。 其中,41% 來自國際駭客,13% 來自已知機器人,7% 來自「幽靈完成」(即受訪者看似已完成問卷,但因設定了重定向連結而未實際收集到任何數據),8% 來自重複填寫(即受訪者完成多份問卷,通常是因他們建立了多個詐騙帳戶,假裝成不同的人口統計群體)。
為確保最高資料品質,我們將詐欺行為分為三種類型:
•缺乏參與度的受訪者:他們邊做其他事情邊填寫問卷,或以機械式方式快速完成問卷,因此準確性存疑。對資料完整性的影響屬中低程度。這類受訪者需要指導與行為監控,可能需要將其排除在某些研究之外。
•不誠實受訪者:他們謊報身分,並完成更多問卷以更快賺取獎勵。對資料完整性的影響程度為中等至高。
•詐欺受訪者:他們單獨或結夥駭入問卷系統,大量賺取獎勵——若您願意,可稱之為新型點擊農場。這屬於嚴重詐欺行為,規模龐大且對資料完整性影響極大。
Kantar 針對這類詐欺行為分別採取了哪些對策?我們又是如何運用業界領先的 AI/生成式 AI 工具來對抗這些詐欺行為的?
•我們致力於 優質的問卷設計:問卷品質取決於設計、長度及使用者體驗。若未考量這些因素,即使是最積極的受訪者也可能失去興趣。
•我們預防因疏忽造成的錯誤:部分受訪者因誤解而給出前後不一的答案,也有些人並非其自稱的身份;但並非所有被標記的問題都源於蓄意欺騙。有些是無心之失,且並非所有被標記的行為都會損害資料完整性。我們希望包容所有真誠的參與者。 因此,我們會為受訪者提供培訓,並在必要時給予改善行為的機會。
•我們定義品質:由於品質具有主觀性,因此我們採用客觀指標。關鍵在於辨識不同層級的品質問題及其成因。Kantar 的 Profiles 部門結合 20 多年深样组 科技及人工智慧,透過其專屬的反詐欺工具 Qubed AI 即時實現此目標。 Qubed AI 具備即時運算能力,由 5 個深度神經網路(亦即先進機器學習)驅動,每日基於 6,000 萬筆以上事件進行訓練,並針對每次調查會話處理超過 300 個特徵,能在數毫秒內自動評分並判定受訪者是否存在詐欺行為,同時提供建議行動——這是人類(及其他反詐欺技術)根本無法做到的。
•我們採用 GenAI 結合 Qubed 開放式驗證:透過基於 ChatGPT 的專有開放式評估解決方案,從多維度對受訪者的開放式回答進行評分。 我們檢測的因素包括:與提問的相關性、原創性、完整性、語言表達、剽竊回答、個人識別資訊(PII)的使用、俚語、縮寫詞的使用,以及粗俗用語、種族歧視、無意義的胡言亂語,以及由 ChatGPT 生成的回答。 欲進一步了解 Kantar 的 Qubed 開放式驗證如何打擊詐欺,請參閱我們先前發表的文章《轉型樣本:Kantar 如何運用大型語言模型來改善样组 ?》
•推出 Qubed 臉部驗證:Kantar 在打擊問卷詐欺方面的最新進展,是將 Realeyes Verify 整合至我們的 Qubed AI 中。 Verify 是一項輕量級人臉驗證技術,其訓練數據源自 1,700 萬次經受訪者同意的調查會話所組成的獨特網路攝影機資料集。我們能迅速識別惡意行為者企圖加入我們的 Premium Panels 的情況。
行銷長與洞察主管需要了解样组 如何優先考量資料品質,並確保样组 能提供及時且準確的資料,且未受欺詐性回應的污染。
隨著整個產業透過《品質承諾》及其他方式致力於提升品質,Kantar 憑藉對人工智慧的智慧運用,已做好充分準備,將持續發揮領導作用,杜絕造假行為,並為消費者數據產業重拾更大信心。

.svg)